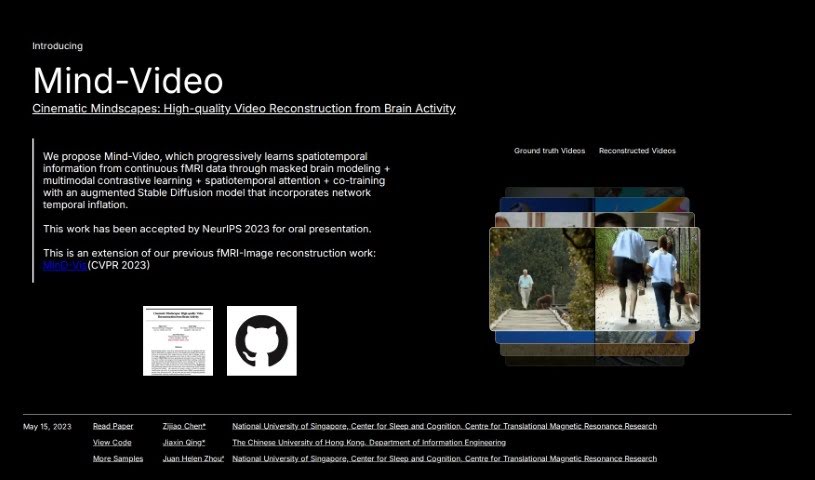
What is Mind Video?
Mind Video is a clever system built with two main parts, designed to connect how we understand images with how we decode brain signals for video. It gradually learns from brain activity, moving through several stages to really get the meaning behind what’s being seen. The model uses unsupervised learning, specifically masked brain modeling, to pick up on visual fMRI features. Then, it hones in on features related to meaning by using contrastive learning within the CLIP space. Finally, these learned features are fine-tuned by training together with a special stable diffusion model made for video generation, all guided by fMRI data. The outcomes are impressive: high-quality videos that are reconstructed with accurate meaning, doing a better job than older methods on both semantic and pixel-level measurements.
Who created Mind Video?
Mind Video was developed by a team including Zijiao Chen, Jiaxin Qing, Tiange Xiang, and Professor Juan Helen Zhou. It was first introduced on June 18, 2024. Mind Video comes from Mind-X, a research group focused on decoding multimodal brain signals using large-scale models. Their main goal is to push the boundaries of brain decoding by using the latest advancements in large models and Artificial General Intelligence (AGI). Ultimately, they aim to create general-purpose brain decoding models that can be used in brain-computer interfaces, neuroimaging, and neuroscience research.
What is Mind Video used for?
- It helps us reconstruct human vision from brain activity, giving us a deeper look into cognitive processes.
- It can recover continuous visual experiences, essentially bringing them back as videos.
- It works to make the generation process more consistent.
- It’s designed to bridge the gap between decoding image and video brain signals.
- It learns features tied to meaning by using datasets that are already annotated.
- It generates reconstructions of videos that are accurate.
- It involves training the fMRI encoder and the stable diffusion model separately, then fine-tuning them together.
- The model learns progressively from brain signals.
- It’s helping to develop brain decoding models that can be used for many different purposes.
- It opens up applications in brain-computer interfaces, neuroimaging, and neuroscience.
- It offers a better understanding of cognitive processes.
- It clearly shows the dominance of the visual cortex.
- It operates with hierarchical encoder layers.
- It preserves volume and time-frames.
- It applies masked brain modeling.
- It uses a large-scale unsupervised learning approach.
- It employs multi-modal contrastive learning.
- It features progressive semantic learning.
- It includes analytical attention analysis.
- It’s 45% better than previous methods.
Who is Mind Video for?
- Neuroscientists
- Researchers in Brain-Computer Interface (BCI)
- Neuroimaging Scientists
- Anyone in Neuroscience
- Those working in Neuroimaging
- Brain-computer interface specialists
- Neuroimaging researchers
- Neurologists
- Psychiatrists
How to use Mind Video?
To get the most out of Mind-Video, here’s a straightforward guide:
- Understand the Goal: First off, remember that Mind-Video is all about closing the gap between decoding images and decoding videos from brain signals. It introduces a two-part system specifically for this.
- Model Training: The Mind-Video model has two modules. They’re trained separately at first, and then fine-tuned together. The initial module uses unsupervised learning to grasp general visual fMRI features and then distills features related to meaning, using annotated datasets. The second module refines these learned features by co-training with a modified stable diffusion model, which is tailored for video generation guided by fMRI data.
- Progressive Learning: As the model works, it progressively learns from brain signals. This helps it build a deeper understanding of the semantic space across several stages within the first module. This includes using multimodal contrastive learning along with spatiotemporal attention for fMRI data broken down into windows.
- Evaluate the Results: Mind-Video has shown really promising outcomes. It generates high-quality videos, captures semantics accurately, and significantly improves semantic metrics and SSIM (Structural Similarity Index Measure) compared to older methods.
- Contribute to the Field: Mind-Video offers a brain decoding pipeline that’s both flexible and adaptable. It really emphasizes learning accuracy, how relevant the semantics are, and making the model interpretable.
By following these steps, you can effectively use Mind-Video for applications that involve decoding images into videos from brain activity.