123RF AI Image Generator
Creative Image Generation
Learn More
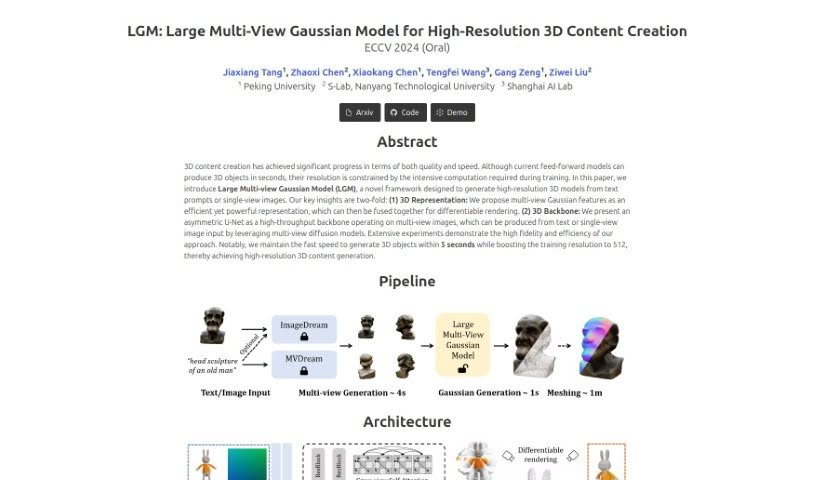
Discover LGM 3D, a powerful tool for creating high-resolution 3D models from text or single images. Learn how it works and how to use it effectively in 2025, plus how it stacks up against other 3D model generators.
LGM 3D, which stands for Large Multi-View Gaussian Model, is a really neat new framework for making high-resolution 3D content. What’s cool about it is how efficiently it can create detailed 3D models, whether you start with text prompts or just a single image. The real innovation here is how it uses multi-view Gaussian features to represent things effectively. Plus, it’s got this asymmetric U-Net backbone that’s built for processing multiple views of an image really fast. This whole setup means LGM 3D can whip up high-fidelity 3D objects in under 5 seconds – pretty amazing, right? It also bumps up the training resolution to 512, showing some serious progress in how we create 3D content, balancing speed and quality really well.
LGM 3D was developed by a talented group of researchers. You’ve got Jiaxiang Tang and Xiaokang Chen from Peking University, Zhaoxi Chen and Ziwei Liu who are part of S-Lab at Nanyang Technological University, and Tengfei Wang from Shanghai AI Lab. Together, they’ve built this LGM framework specifically to generate high-resolution 3D models quickly, using either text prompts or single-view images. It’s a big step forward in the world of 3D content creation.
Using LGM 3D is pretty straightforward. Here’s a quick rundown of the steps:
By following these steps, you can easily use LGM 3D to create detailed, high-resolution 3D models from your text prompts or single images, and do it all quite efficiently.
Discover more tools in similar categories that might interest you
Get weekly updates on the latest AI tools, trends, and insights delivered to your inbox
Join 25,000+ AI enthusiasts. No spam, unsubscribe anytime.